Introduction
In distributed systems, handling long-running tasks without blocking the main API is a classic problem. While tools like Celery or Redis are popular, they introduce significant operational complexity. For data archiving needs, I designed a simpler, “boring” solution that leverages existing infrastructure: PostgreSQL.
The Challenge: Reliable Data Archiving
I needed to periodically archive sensitive data from an active database to Azure Blob Storage. The requirements were strict:
- Persistence: Jobs must survive server restarts.
- Reliability: No data could be left in a “limbo” state.
- Simplicity: No new infrastructure components (like Redis or RabbitMQ) to manage.
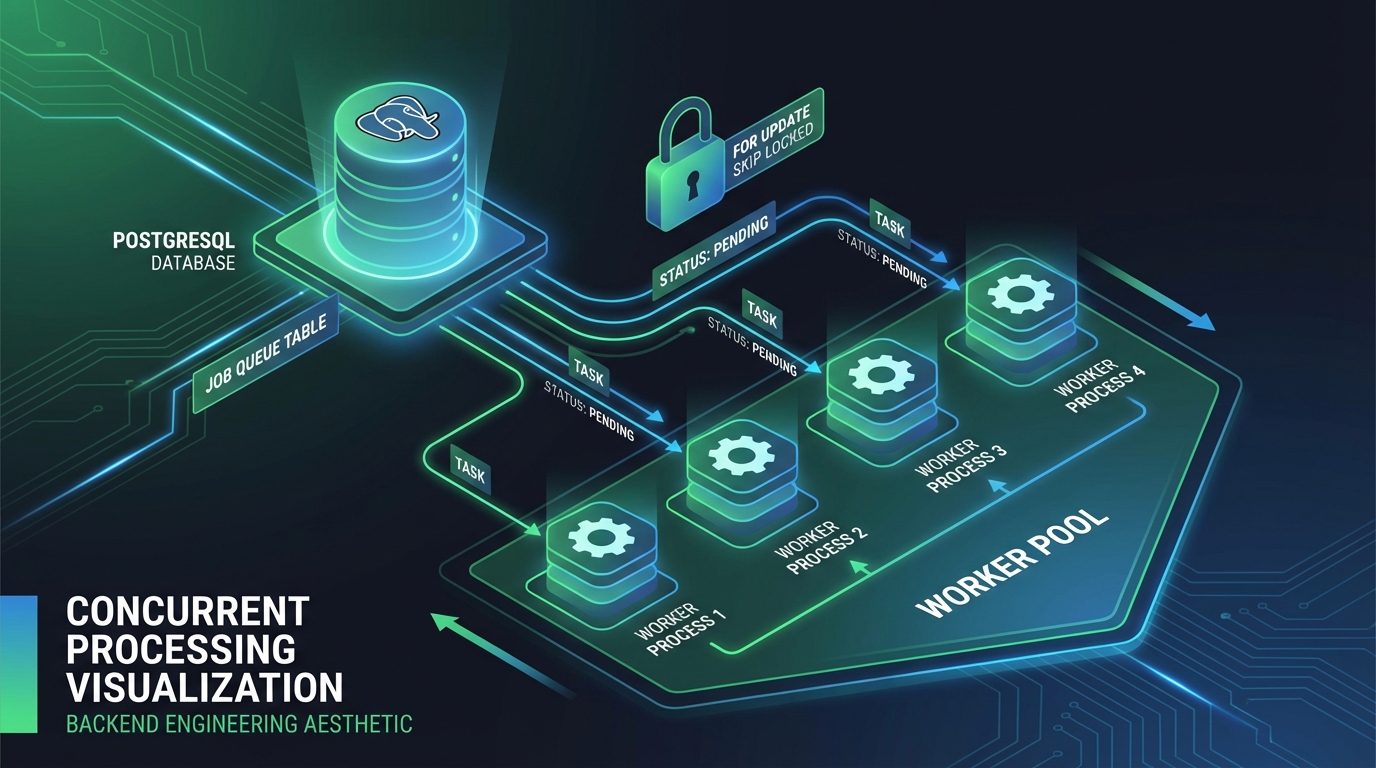
The Solution: The “PostgreSQL as a Queue” Pattern
I implemented a custom worker system where the database itself acts as the job queue.
graph TB
subgraph "Job Producers"
API[API Server]
Scheduler[Cron Scheduler]
end
subgraph "PostgreSQL Database"
Queue[(background_jobs table)]
Data[(Application Data)]
end
subgraph "Worker Instances"
W1[Worker 1]
W2[Worker 2]
W3[Worker N]
end
subgraph "External Services"
Azure[Azure Blob Storage]
end
API -->|INSERT job| Queue
Scheduler -->|INSERT job| Queue
Queue -->|FOR UPDATE SKIP LOCKED| W1
Queue -->|FOR UPDATE SKIP LOCKED| W2
Queue -->|FOR UPDATE SKIP LOCKED| W3
W1 -->|Archive Data| Azure
W2 -->|Archive Data| Azure
W3 -->|Archive Data| Azure
W1 -->|UPDATE status| Queue
W2 -->|UPDATE status| Queue
W3 -->|UPDATE status| Queue
W1 -->|Read| Data
W2 -->|Read| Data
W3 -->|Read| Data1. The Job Table
I created a background_jobs table to store task state.
CREATE TABLE background_jobs (
id UUID PRIMARY KEY,
task_name VARCHAR NOT NULL,
payload JSONB,
status VARCHAR DEFAULT 'queued', -- queued, running, completed, failed
created_at TIMESTAMP DEFAULT NOW()
);2. The Worker Loop
The core innovation is how the worker fetches jobs. I use the FOR UPDATE SKIP LOCKED clause, which is a game-changer for building queues in Postgres.
# Simplified worker logic
async def fetch_next_job():
async with db.transaction():
# This query atomically locks the row, preventing other workers
# from grabbing the same job.
query = """
SELECT * FROM background_jobs
WHERE status = 'queued'
ORDER BY created_at ASC
LIMIT 1
FOR UPDATE SKIP LOCKED
"""
job = await db.fetch_one(query)
if job:
await mark_as_running(job.id)
return jobThis allows us to run multiple worker instances in parallel without race conditions. If one worker crashes, the transaction rolls back, and the job becomes available for another worker immediately.
3. Process Management
I use Supervisor to keep the Python worker script running. If it crashes, Supervisor restarts it instantly. This, combined with the transactional integrity of PostgreSQL, guarantees that jobs are eventually processed even in the face of failure.
Why Not Celery?
Celery is powerful but heavy. For this use case—processing a few hundred archive jobs a day—it would have been overkill. By using PostgreSQL, I:
- Eliminated the need for a message broker (Redis/RabbitMQ).
- Gained “free” persistence and transactional guarantees.
- Kept the operational footprint small.
Conclusion
Sometimes the best tool for the job is the one you already have. By understanding the advanced locking features of PostgreSQL, I built a robust, persistent background job system with zero extra infrastructure cost.
Tags
