Introduction
In a microservices ecosystem, reliable event delivery is the backbone of consistency. I recently implemented an event orchestration system that bridges the gap between legacy applications and a modern platform using AWS EventBridge and SQS.
The Challenge: Long-Running Workers & Reliability
I needed a worker service that could:
- Consume events from multiple sources.
- Reliably dispatch them to downstream subscribers (webhooks).
- Run indefinitely without crashing due to expired credentials.
- Guarantee “at-least-once” delivery without processing duplicates.
Key Implementation Details
1. Robust Session Management
One common pitfall with long-running Python workers on AWS is token expiration. Standard boto3 sessions can time out.
I implemented a singleton AWSSession class that wraps the STS assume_role logic. It proactively checks if the session is valid before every operation and automatically renews the token if it has expired. This “self-healing” capability ensures our workers can run for weeks without interruption.
# Simplified logic
def get_session(self):
try:
self.session.client("sts").get_caller_identity()
except ClientError as error:
if error.response["Error"]["Code"] == "ExpiredToken":
self._initialize_session() # Auto-renew
return self.session2. The Fan-Out Architecture
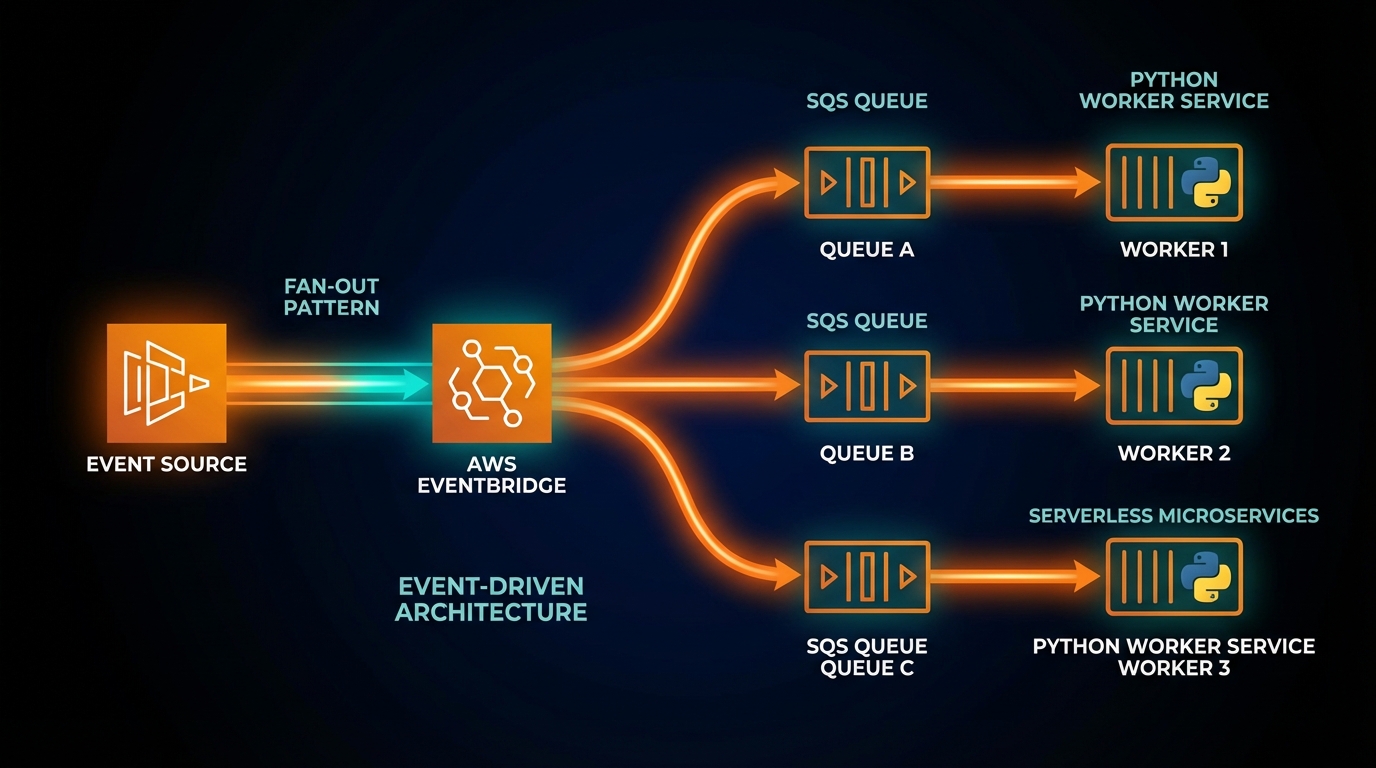
I use EventBridge as the central nervous system.
- Producers (Legacy App, Modern App) push events to a central Event Bus.
- Rules on the Event Bus route these events to an SQS Queue.
- The Python Worker polls this queue.
This decouples the producers from the consumers. If the worker is down for maintenance, events simply pile up in the SQS queue, ready to be processed when it’s back online.
graph LR
Legacy[Legacy App] -->|PutEvents| EB[EventBridge Bus]
Modern[Modern App] -->|PutEvents| EB
EB -->|Rule: All Events| SQS[SQS Queue]
subgraph "Worker Service"
Worker[Python Worker]
Session[AWS Session Manager]
end
SQS -->|Poll| Worker
Worker -->|Renew Token| Session
Worker -->|Check Idempotency| DB[(Database)]
Worker -->|Dispatch| Webhook[External Webhook]3. Idempotency & Delivery Guarantees
SQS guarantees “at-least-once” delivery, which means the system might receive the same message twice. To handle this, I implemented an idempotency check at the database level.
Before processing a message, the service checks if its unique MessageId has already been handled.
- If yes: The system acknowledges and deletes the message immediately.
- If no: It processes it, dispatches the webhook, and then saves the record.
This ensures that even if a network error causes a retry, the system never triggers the same side-effect twice.
Database Schema
The following is an example of table models that can be used for this pattern. This design is database-agnostic and can be implemented in PostgreSQL, MySQL, or even NoSQL stores.
Here is the core model to track processed messages and ensure idempotency:
Table: ProcessedMessages
------------------------
id String (Primary Key) // SQS MessageId
source String // Event Source (e.g., "legacy-app")
content JSON // The full event payload
processed_at Timestamp // When it was handledAnd the delivery attempts log, which is crucial for debugging webhook failures:
Table: DeliveryAttempts
-----------------------
id String (Primary Key)
message_id String (Foreign Key to ProcessedMessages)
status String // 'success', 'failed', 'pending'
response_code Integer // HTTP Status Code (e.g., 200, 500)
response_body Text // Error message or response content
attempted_at TimestampConclusion
By combining the routing power of EventBridge with the buffering capabilities of SQS and a robust Python consumer, I created an event infrastructure that is both resilient and scalable.
Tags
